A Deep Analysis of Arisyn’s Product CapabilitiesAn Automatic Data Relationship Platform for Real-World Data Integration
- Arisyn

- Nov 27, 2025
- 3 min read
Updated: Dec 15, 2025
1. Arisyn’s Mission
In one sentence:
Arisyn’s mission is to enable automatic data relationship discovery in data integration scenarios.
This definition can be further expanded as follows:
Application ScopeArisyn is designed for data integration use cases.
At the simplest level, this includes relationships between multiple tables within the same system.
At higher complexity, it supports relationship discovery across heterogeneous, multi-source data environments.
Core Requirement of Data IntegrationAny data integration task fundamentally requires the establishment of inter-table relationships.
PreconditionThe data to be integrated must contain implicit or explicit relational signals that can be discovered.
Under these conditions, Arisyn’s goal is straightforward:
When users specify the data they want to integrate—expressed as a set of tables and fields—Arisyn automatically generates valid and usable data relationship paths.
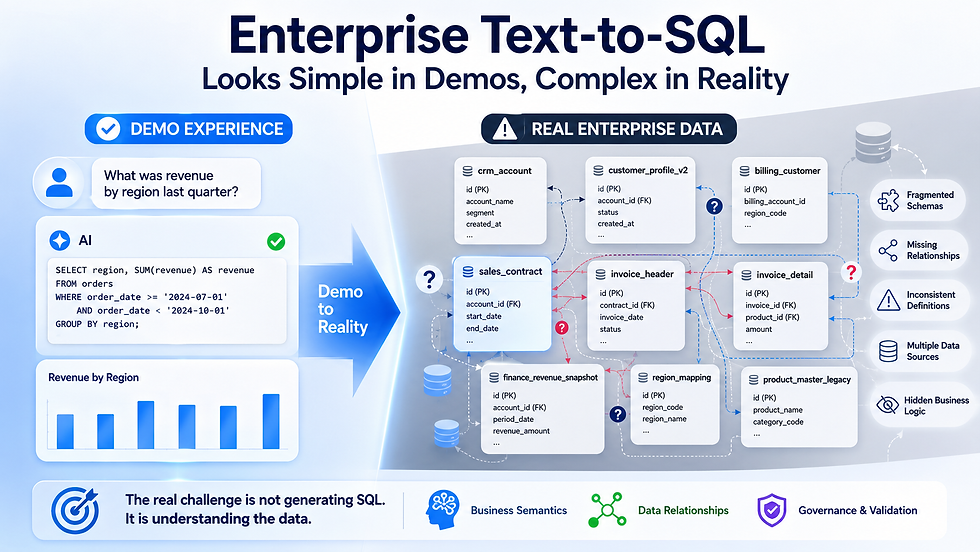
2. What Problem Does Arisyn Solve?
To illustrate Arisyn’s value, we use a deliberately complex but realistic example.The complexity is intentional: it is precisely in such scenarios that Arisyn’s product value becomes evident.
3. Example Scenario: A University Data Environment
3.1 Department Information (Table T_A)
Each department has a short identifier.
DEPARTMENT_ID | DEPART_NAME |
GEO | School of Geology |
IT | School of Information Engineering |
3.2 Class Information (Table T_B)
Each department contains multiple classes.Class IDs are composed of enrollment year + sequence number.
CLASSES_ID | CLASSES_NAME | DEPARTMENT |
2020_01 | Geo 20 (1) | GEO |
2020_02 | Geo 20 (2) | GEO |
(Highlighted fields represent target output fields in later steps.)
3.3 Student Information (Table T_C)
Each student has a globally unique student ID.
STUDENT_ID | STUDENT_NAME | CLASSES |
202000001 | Zhang San | 2020_01 |
202000002 | Li Si | 2020_02 |
3.4 Course Information (Table T_D)
Each course has a code, full score, and credit value.
CLASS_CODE | CLASS_TITLE | FULL_SCORE | CREDIT |
MATH_01 | Advanced Math I | 100 | 4 |
MATH_02 | Advanced Math II | 100 | 4 |
ENGLISH_LV1 | English I | 100 | 2 |
CHEMISTRY | Chemistry | 10 | 2 |
3.5 Department-Specific Passing Criteria (Table T_E)
Different departments have different passing thresholds for the same course.
DEPARTMENT | CLASS | PASS_SCORE |
GEO | MATH_02 | 60 |
IT | MATH_02 | 75 |
3.6 Student Exam Results (Table T_F)
Each student receives scores per course per term.
STUDENT_ID | TERM | CLASS | SCORE |
202000001 | 2023_1 | MATH_02 | 85 |
202000001 | 2023_1 | ENGLISH_LV1 | 92 |
202000002 | 2023_1 | MATH_01 | 78 |
4. The Business Requirement
List each student’s courses in the 2023_1 term, their achieved scores, and the corresponding passing score.
Expected output:
Class | Name | Term | Course | Passing Score | Actual Score |
Geo 20 (1) | Zhang San | 2023_1 | Advanced Math II | 60 | 85 |
... | ... | ... | ... | ... | ... |
5. Why This Is Harder Than It Looks
At first glance, this looks like a standard multi-table SQL join.
In reality:
T_F contains student scores
T_E contains department-specific passing criteria
But these two tables alone are insufficient to produce the result:
All identifiers are encodedCourse names, class names, and department names must be resolved.
Student-to-department mapping is indirectStudents belong to classes; classes belong to departments.The department is not directly stored in the exam results.
A correct SQL query therefore requires:
Multiple intermediate joins
Correct inference of hidden business logic
Accurate navigation through indirect relationships
6. Where Arisyn Fits In
In this scenario:
Blue elements represent user-defined query conditions (e.g., term = 2023_1)
Yellow elements represent inferred tables, joins, and relationship paths
Arisyn automatically generates the yellow part.
The user only needs to specify:
What data they want
Under what conditions
Arisyn determines:
Which tables must be used
How those tables are logically connected
7. Why Manual SQL Is Not the Real Problem
Many engineers might argue:
“Writing this SQL is trivial.”
That statement is technically true — but operationally misleading.
Now place this requirement in a real enterprise environment:
Dozens of systems (student management, research, HR, campus access, facilities, etc.)
Hundreds or thousands of tables
Tens of thousands of fields
Multiple teams, vendors, and stakeholders
The requester is often:
A business administrator, not an engineer
Unaware of where data physically resides
The implementation team:
May not know all systems involved
Relies on fragmented institutional knowledge
In practice:
SQL coding is often less than 25% of total effort
The majority of time is spent on:
Requirement interpretation
Data source discovery
Data standard alignment
Relationship validation and trial-and-error
These efforts are:
Manual
Non-reusable
Lost when people leave projects
8. The Core Problems Arisyn Solves
Arisyn fundamentally restructures the data integration workflow:
Developers focus on business objectives, not hidden data logic
Only target fields need to be specified — not intermediate tables
Join relationships no longer need to be manually designed
By addressing these issues, Arisyn delivers:
Elimination of most data analysis overhead
Dramatic reduction in trial-and-error
Up to 90% reduction in integration workload
10× or greater overall efficiency improvement
9. Summary
Arisyn does not make SQL faster.
It makes data integration fundamentally scalable.
By transforming implicit, fragile, human-dependent data knowledge into an automated, reusable system capability, Arisyn enables data teams to focus on value creation instead of data archaeology.

Comments