Why Enterprise Text-to-SQL Fails After the Demo
- Arisyn

- Jun 10, 2024
- 7 min read
The first time someone sees a good Text-to-SQL demo, it feels almost inevitable.
A user types a business question in plain English. The system understands the request, writes SQL, runs the query, and returns a clean answer with a chart. For business teams, it looks like the end of reporting backlogs. For data teams, it looks like a way to scale analytics without writing every query by hand. For executives, it looks like AI finally becoming useful inside the enterprise.
Then the demo meets a real company database.
That is where the problem begins.
Most enterprise Text-to-SQL systems do not fail because the language model cannot write SQL. Modern models are often quite good at producing syntactically valid SQL. The real problem is that enterprise data is messy, fragmented, inconsistent, and full of undocumented business context.
A query can be valid SQL and still return the wrong answer.
That is the gap many demos hide.
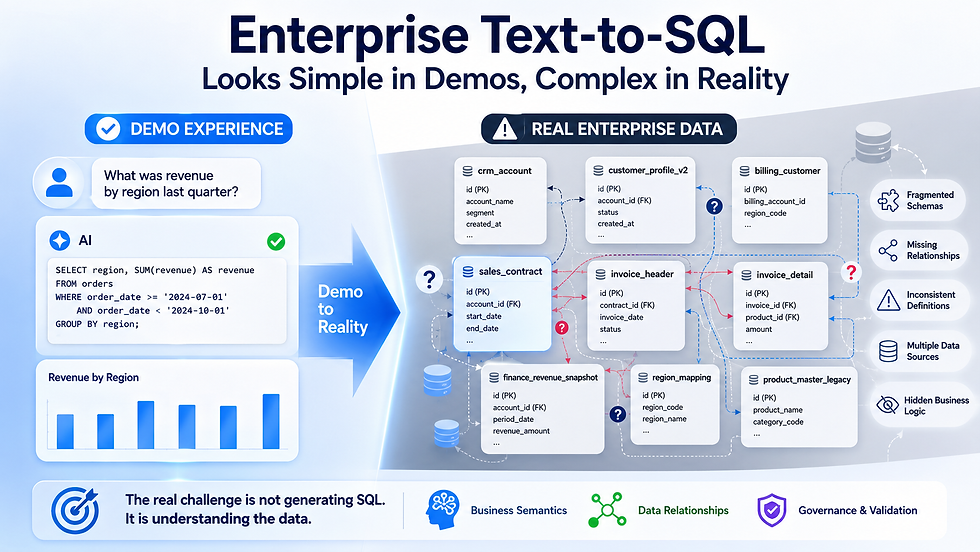
The Demo Dataset Is Not the Enterprise Dataset
A demo usually starts with a clean schema:
customers
orders
order_items
products
regionsThe tables are well named. The relationships are obvious. The foreign keys are present. The metric definitions are simple. If a user asks, “What was revenue by region last quarter?” the system can infer the path quickly.
Enterprise data rarely looks like that.
Real environments often include tables like:
crm_account
customer_profile_v2
sales_contract
invoice_header
invoice_detail
region_mapping
finance_revenue_snapshot
product_master_legacySome tables are created for applications, not analytics. Some fields are deprecated but still populated. Some relationships are never declared as foreign keys. Some business logic lives in stored procedures, Excel files, analyst notebooks, or simply in the memory of senior data people.
The model may still generate SQL. The dangerous part is that the SQL may look reasonable.
It may even run successfully.
But a successful query is not the same as a trusted answer.

The Real Problem Is Missing Context
When a business user asks:
What was revenue last quarter by region?
That question is not just a language task.
The system has to understand several things before generating SQL:
What does “revenue” mean?
Is it booked revenue, recognized revenue, invoiced revenue, or paid amount?
Which table contains the approved revenue value?
Which date defines “last quarter”?
How is region assigned?
Should cancelled orders be excluded?
Which customer table is authoritative?
Which join path avoids duplicate rows?
Which definition will finance accept?
Without this context, the model has to guess.
In enterprise analytics, guessing is not a feature. It is a risk.
This is why prompt engineering alone is not enough. A better prompt may help the model explain itself more clearly, but it does not magically create trusted metadata, governed metrics, or reliable table relationships.
The core issue is not only how the question is phrased.
The core issue is whether the system understands the data well enough to answer.
Why Schema-Only Prompting Breaks Down
Many Text-to-SQL systems start by passing table names, column names, and maybe a few descriptions into the prompt.
That can work for small use cases.
It breaks down when the data environment becomes large, old, or cross-functional.
A schema can tell the model that a column exists. It does not always tell the model whether that column should be used.
For example, a database may contain multiple customer-related tables:
customer
crm_account
billing_customer
customer_profile
customer_snapshotA language model can see all of them. But which one is the source of truth? Which one is current? Which one should be used for sales analysis, billing analysis, or support analysis?
The same issue appears with metrics.
A column named amount may represent order amount, invoice amount, paid amount, adjusted amount, or net revenue after returns. A model can guess from names, but the business may require a specific definition.
The same issue appears with joins.
A join between two tables may be technically possible but analytically wrong. It may duplicate rows. It may mix transaction-level data with snapshot-level data. It may connect records through a weak relationship that should not be used for financial reporting.
This is why enterprise Text-to-SQL needs more than schema visibility.
It needs governed context.
Semantic Layers Help, But They Are Not the Whole Answer
A semantic layer is a major step forward.
It gives business meaning to data. It maps business terms, metrics, and dimensions to tables and fields. It helps ensure that “revenue,” “active customer,” “inventory balance,” or “gross margin” mean the same thing across teams.
For enterprise AI analytics, semantic governance is essential.
But a semantic layer alone does not solve every problem.
Even if the system knows what a business term means, it still needs to know how the relevant data is connected.
For example, suppose the system understands:
“Revenue” maps to an approved finance metric.
“Customer segment” maps to a customer dimension.
“Last quarter” maps to a time filter.
That is useful. But SQL generation still needs the correct relationship path between revenue, customers, segments, contracts, invoices, products, and time dimensions.
If the join path is wrong, the answer is wrong.
This is where data relationship context becomes critical.
The Missing Layer: Data Relationship Discovery
In many companies, data relationships are not fully documented.
Foreign keys may be incomplete. Table relationships may exist only through naming conventions, overlapping values, historical usage, or analyst knowledge. Cross-system relationships may never have been formally modeled.
A senior analyst often becomes the human relationship engine. They know which table is safe, which field should be avoided, which join works, and which metric definition leadership expects.
That knowledge is valuable. But if it only lives in people’s heads, it does not scale.
A relationship-aware Text-to-SQL system should be able to help identify and manage:
which tables are related
which fields can be used as join keys
how strong or reliable a relationship appears to be
which relationship path should be preferred for a query
where ambiguity or risk exists
which relationships should be governed, reviewed, or excluded
This changes the role of the language model.
Instead of asking the model to infer everything from raw table names, the system provides structured context before SQL generation.
The model is no longer guessing in the dark. It is working within a governed data environment.

A More Reliable Enterprise Text-to-SQL Workflow
A simple demo workflow looks like this:
user question → LLM → SQL → answerThat may be enough for a small demo.
A production-grade enterprise workflow should look more like this:
user question
→ intent understanding
→ business semantic mapping
→ metadata retrieval
→ data relationship discovery
→ join path selection
→ SQL generation
→ validation
→ execution
→ explanationThis workflow is less magical, but much more reliable.
The goal is not just to generate SQL. The goal is to generate SQL that is aligned with business definitions, data relationships, permissions, and validation rules.
That distinction matters.
A business user does not only want an answer. They want an answer they can trust.
A data team does not only want automation. They want automation that does not create new governance problems.
An enterprise does not only want a chat interface. It wants a controlled way to make structured data queryable by AI.
Validation Is Not Optional
SQL validation is often treated as a final technical check. In enterprise analytics, it should be part of the core workflow.
A reliable system should be able to check for issues such as:
invalid columns or tables
unsafe joins
missing filters
row duplication risk
conflicting metric definitions
ambiguous business terms
permission boundaries
unsupported query scope
incomplete relationship context
When the system is uncertain, it should not pretend to know.
It should ask a clarifying question.
For example:
Do you mean booked revenue or recognized revenue?
Or:
There are multiple customer tables available. Should this query use CRM accounts or billing customers?
This is not a weakness. It is a sign of a safer system.
In real enterprise environments, a system that asks the right clarification question is often more valuable than a system that confidently returns a wrong answer.

Why Better Prompts Are Not Enough
Prompt engineering is useful. Better prompts can improve structure, tone, reasoning steps, and SQL formatting.
But prompts cannot replace the data foundation.
A prompt cannot reliably tell the model which table is authoritative if that information has not been captured. A prompt cannot invent a trusted join path across fragmented systems. A prompt cannot enforce metric governance if the business definition is missing. A prompt cannot know which data relationships are valid unless the system provides that context.
The most important improvement is not a longer prompt.
It is a better governed context layer.
For enterprise Text-to-SQL, the most important question is not:
Which model should we use?
The better question is:
What trusted context does the model receive before it writes SQL?
What Enterprise Teams Should Look For
When evaluating a Text-to-SQL or AI analytics solution, enterprise teams should ask practical questions:
How does the system understand business terms?
Can it map metrics and dimensions to governed definitions?
How does it discover table relationships?
Can it identify preferred join paths?
Does it validate SQL before execution?
Can it explain why a query was generated?
Does it handle ambiguity by asking clarifying questions?
Can it work across multiple data sources?
Does it provide auditability and governance?
Can data teams improve the system over time?
These questions are less exciting than a polished demo.
They are also much closer to what determines production success.
How Arisyn Approaches the Problem
At Arisyn, we approach enterprise Text-to-SQL as a governed data reasoning workflow, not just a natural language interface.
Our view is simple: reliable AI analytics for structured enterprise data requires more than an LLM. It needs business semantics, metadata, data relationship discovery, SQL validation, workflow orchestration, and feedback loops.
Arisyn is designed to help enterprise teams make structured data more queryable by AI through a combination of semantic governance and relationship-aware query generation.
The goal is not to replace data teams.
The goal is to help data teams turn scattered technical knowledge into reusable, governed context that AI systems can use safely.
That includes:
defining business metrics and dimensions
mapping business terms to data structures
discovering relationships between tables and fields
selecting trusted join paths
generating and validating SQL
explaining results in a way business users can understand
supporting governance, auditability, and continuous improvement
This is the foundation required for enterprise AI analytics to move from impressive demos to reliable production workflows.
The Takeaway
Enterprise Text-to-SQL does not fail because AI cannot write SQL.
It fails when the system lacks the context required to write the right SQL.
The difference matters.
A model can produce a query. But a trusted enterprise analytics system must understand business meaning, metadata, table relationships, permissions, validation rules, and uncertainty.
The future of AI-powered data querying will not be won by the prettiest chat interface.
It will be won by systems that understand enterprise data well enough to answer with confidence.
For Text-to-SQL to become truly useful in production, it has to stop being treated as a translation problem.
It has to become a governed, relationship-aware data workflow.
That is the future Arisyn is building toward.



Comments